
슬코생
[kaggle] Bike Sharing Demand 공공자전거 수요 예측 모델 #2 본문
✔ 연도-월로 나타내기
# 월별 데이터 모아보기
def concatenate_year_month(datetime):
return "{0}-{1}".format(datetime.year, datetime.month)
train["year_month"] = train["datetime"].apply(concatenate_year_month)
print(train.shape)
train[["datetime", "year_month"]].head()fig, (ax1, ax2) =plt.subplots(nrows=1,ncols=2)
fig.set_size_inches(18,4)
sns.barplot(data=train, x="year",y="count",ax=ax1)
sns.barplot(data=train, x="month",y="count",ax=ax2)
fig, ax3 = plt.subplots(nrows=1, ncols=1)
fig.set_size_inches(18,4)
sns.barplot(data=train, x="year_month",y="count",ax=ax3)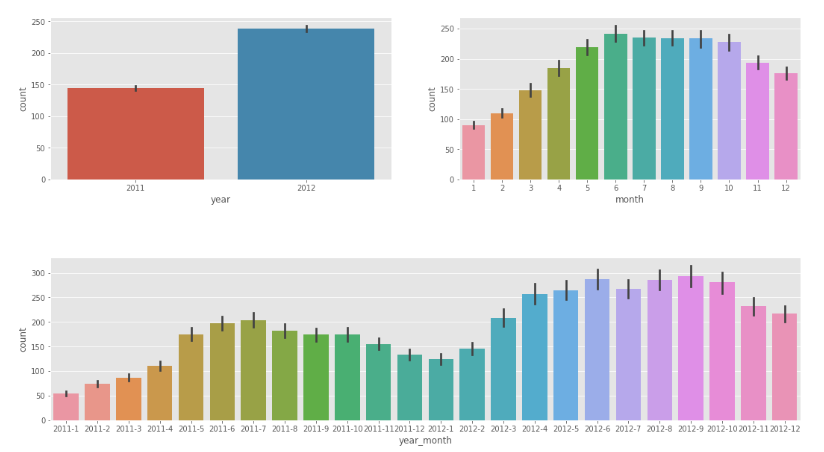
✔ 분석 결과
위의 코드는 outlier를 줄여주는 코드!

count 변수가 오른쪽에 치우쳐져 있음.
대부분의 기계학습은 normal이어야 하기에 정규분포를 갖는 것이 바람직하다.
대안으로 outlier data를 제거하고 "count" 변수에 로그를 씌워 변경해봐도 정규분포를 따르지는 않지만 이전 그래프보다 좀 더 자세히 표현하고 있다.
결과는 3탄에서!
'Data > Project' 카테고리의 다른 글
| [kaggle] Bike Sharing Demand 공공자전거 수요 예측 모델 #3 (0) | 2020.01.29 |
|---|---|
| [kaggle] Bike Sharing Demand 공공자전거 수요 예측 모델 #1 (0) | 2020.01.29 |
| [멋쟁이 사자처럼 7기] django 이용해 wordcount 해보기 (0) | 2020.01.29 |
| 오늘코드 '공공데이터를 활용한 python 기반의 스타벅스/이디야 분석' 박조은님 (0) | 2020.01.29 |
'Data/Project' Related Articles
more



Comments